
Почему меняется постоянно информация в интернете?
Тест с ответами “Поиск информации в интернете” 10 класс
1. Если ключевые слова были выбраны неудачно, то:
а) URL-адреса документов могут быть слишком большим +
б) URL-адреса документов могут не найти
в) URL-адреса документов могут быть слишком маленькими
2. Web-браузер:
а) компьютер, на котором работает сервер-программа WWW
б) клиент-программа WWW, обеспечивающая пользователю доступ к информационным ресурсам Интернета +
в) сеть документов, связанных между собой гиперссылками
3. К чему сводится поиск информации в каталоге:
а) к информационным порталам
б) к современным поисковым системам
в) к выбору определенного каталога +
4. Выберите из предложенного списка IP-адрес:
а) 193.126.7.29 +
б) 1.256.34.21
в) 34.89.45
5. Что осуществляется с помощью специальных программ-роботов:
а) поисковые системы общего назначения
б) поиск по ключевым словам
в) заполнение баз данных поисковых систем +
6. Поисковой системой не является:
а) Google
б) FireFox+
в) Rambler
7. Для поиска информации в Интернете используют:
а) поисковые системы общего назначения
б) различные механизмы поиска
в) специальные поисковые серверы +
8. Поисковые системы располагаются на специально выделенных компьютерах с мощными каналами связи, так ли это:
а) да +
б) нет
в) отчасти
9. Наиболее полный многоуровневый иерархический тематический каталог русскоязычных Интернет-ресурсов имеет поисковая система:
а) Яндекс
б) Рунет
в) Апорт +
10. Браузер-это:
а) поисковая программа которая является частью поисковой системы
б) программа которая помогает перемещаться по интернету +
в) Web-страница
11. Поисковая система , которая имеют более 200 миллионов документов:
а) Rambler +
б) Google
в) Апорт
12. Что не является браузером:
а) Rambler +
б) Mozila firefox
в) Google Сhrome
13. Поисковая система , которая имеют более 200 миллионов документов:
а) Yandex +
б) Google
в) Рунет
14. Что не является типом поиска:
а) поиск по всем словам
б) поиск по любому из слов
в) поиск по образу +
15. Наиболее полная и мощная поисковая система, в которой хранятся 8 миллиардов Web-страниц:
а) Google +
б) Yandex
в) Rambler
16. Что не является поисковой системой:
а) Rambler
б) Google Сhrome +
в) Google
17. Почему меняется постоянно информация в интернете:
а) архивируются старые Web-сайты и страницы
б) сохраняются старые Web-сайты и страницы
в) создаются новые Web-сайты и страницы +
18. Браузером является:
а) Linux
б) Android
в) Mozilla Firefox +
19. Почему меняется постоянно информация в интернете:
а) меняется внешний вид Web-сайтов и страниц
б) архивируются старые Web-сайты и страницы
в) удаляются старые Web-сайты и страницы +
20. Чтобы найти значение слова «Целесообразно» в Интернете, необходимо использовать поиск:
а) по слову +
б) по словосочетанию
в) по предложению, в котором есть это слово
21. Почему меняется постоянно информация в интернете:
а) меняются URL-адреса +
б) сохраняются старые Web-сайты и страницы
в) меняется внешний вид Web-сайтов и страниц
22. Чтобы найти стих в Интернете, зная его часть, наиболее оптимальным способом, необходимо использовать поиск по:
а) любому слову из предложения
б) фразе со знаками или без знаков препинания +
в) инициалам автора стихотворения
23. Что содержит интерфейс поисковых систем общего назначения:
а) разделы
б) графу
в) список разделов каталога +
24. Что такое URL:
а) группа компьютеров, объединённых по некоторому признаку
б) универсальный адрес документа в Интернете +
в) адрес компьютера в сети
25. Что содержит интерфейс поисковых систем общего назначения:
а) части
б) строфу
в) поле поиска +
26. Выберите домен верхнего уровня в Интернете, принадлежащий России:
а) rus
б) ru +
в) rf
27. Разные поисковые сервисы могут использоваться в:
а) различных механизмах поиска +
б) только в одинаковых механизмах поиска
в) кодировании информации
28. Режим связи с Web-сервером в реальном времени:
а) off-line режим
б) нет такой связи
в) on-line режим +
29. Разные поисковые сервисы могут использоваться в:
а) предоставлении пользователю информации +
б) архивировании информации
в) кодировании информации
30. Что такое гиперссылка:
а) примечание к тексту
б) указатель на другой Web-документ +
в) выделенный фрагмент текста
Поиск информации в сети Интернет
Вы будете перенаправлены на Автор24
Интернет — это глобальная компьютерная сеть, которая объединяет миллионы компьютеров во всем мире в единую информационную систему.
Введение
Существуют следующие основные способы нахождения требуемой информации в сети Интернет:
Указание адреса нужной страницы. Осуществление просмотра гиперссылок и перемещение по ним. Реализация поиска с помощью специальных поисковых систем.
По статистическим данным отдельных источников популярность разных поисковых систем, применяемых пользователями интернета в нашей стране, следующая:
- Поисковая система Яндекс используется 53,9 % пользователей.
- Поисковая система Google используется 35 % пользователей.
- Поисковая система Mail.ru используется 8,3 % пользователей.
- Поисковая система Rambler используется 0,9 % пользователей.
Готовые работы на аналогичную тему
- Поиск в Яндекс картинках производят 0,6 % пользователей.
- Поиск в Google картинках производят 0,2 % пользователей.
Поиск информации в сети Интернет
Любая поисковая система при осуществлении операций поиска осуществляет следующую очерёдность процедур:
- Осуществление сбора информации роботом пауком, который предназначен для поиска.
- Осуществление индексирования информации.
- Осуществление поиска в информации, которая прошла индексацию.
Осуществление сбора информационных данных роботом пауком реализуется в два прохода. Прежде всего, выполняется скачивание веб-страницы, а далее осуществляется анализ имеющихся ссылок. Скачивание реализуется программой Spider, называемой быстрым поисковым пауком, которая поочерёдно выполняет перебор и скачивание веб-страниц для их последующего анализа.
Данная программа получает с различных сайтов веб-страницы по определённому алгоритму и затем выполняет их передачу следующей программе, именуемой Crawler. Эта программа считается медленным пауком анализатором, и она должна обнаружить все ссылки и сформировать дальнейшую программу действий для быстрого паука. Spider обладает некоторым перечнем сайтов, подлежащих посещению, которые заранее были подготовлены другими поисковыми подсистемами. Из этого списка Spider может получить всю необходимую информацию.
После завершения сбора информации, следует выполнение её индексации. Программа индексации реализует сортировку всей предоставленной пауками информации таким образом, чтобы в дальнейшем с ней было просто работать. Она по частям выполняет анализ содержимого страницы. Осуществляется выделение из станицы заголовков, ссылок, текстовой информации, структурных элементов и тому подобное. Вся информация далее должна быть подвергнута структуризации по специализированному алгоритму, и затем сформированные данные поступают в информационную базу.
Далее выполняется поиск в совокупности проиндексированной информации. Это этап определения итогов, на котором выполняется анализ полученной базы. Подсистема определяет, какие из найденных страниц соответствуют запросу пользователя, и показывает итоги поисковых операций. Отбор требуемых результатов реализуется согласно следующим критериям:
- Наличие ключевого слова в заголовке.
- Наличие ключевого слова в доменном имени или адресе страницы.
- Исследование стилевого формата текста на странице. То есть, используются ли типы текста «Жирный» или «Курсив», используются ли различные типы заголовков.
- Выполнение анализа частоты применения ключевого слова на странице, то есть «плотность» использования ключевого слова.
- Осуществление анализа совпадений в области расположения метаданных.
- Реализация проверки наличия ссылок на странице и их направления, и есть ли ключевое слово в текстовой ссылке.
- Реализация проверки, откуда идут ссылки на изучаемую страницу. Выполнение анализа текста ссылки.
- Осуществление проверки ссылок внутри страницы.
В результате этих операций сравнения, поисковая подсистема находит требуемые веб-страницы и предоставляет их пользователю, который сделал поисковый запрос.
В действительности может быть найден любой тип информации, которая является общедоступной в сети интернет, и не попадает под запрет политики системы поиска. Когда пользователь осуществляет поиск какой-либо информации в сети интернет, ему следует иметь в виду следующие моменты:
- Фактически вся информация, находящаяся в сети Интернет, не проходит жёсткий контроль, и любой пользователь, который имеет персональный компьютер с выходом в интернет, может выложить в сеть любую информацию. Это значит, что всегда есть вероятность присутствия в сети недостоверной информации.
- Иногда отсутствует возможность определить истинного автора информации.
- Часто источник информации тоже неизвестен.
- Найденные информационные сообщения часто носят предвзятый характер, их целью является введение в заблуждение, и часто они являются просто недостоверными.
- Может быть не проставлена дата публикации информации, что может поставить под сомнение её актуальность.
Чаще всего пользователь ищет поиском в интернете следующие темы (они располагаются в порядке убывания частоты запросов):
- Разные социальные сети (в контакте, одноклассники и тому подобное).
- Запросы порнографию.
- Разные кинофильмы.
- Различные картинки.
- Музыкальные произведения.
Примерно три процента от всех приходящих в поиск запросов сформулированы в форме вопросов. В максимальном количестве данных запросов в качестве первого слова, используются: какой, сколько, кто. Необходимо выделить ещё одну сегодняшнюю тенденцию, примерно десять процентов запросов содержат прямое действие, то есть, купить, продать или что-либо получить. Наиболее употребляемым уточнением в сегодняшнем российском сегменте интернета являются слова «скачать» и «бесплатно».
При поиске по изображению можно использовать сервис нахождения картинок на основании цифрового кода изображения от Google.
Почему меняется постоянно информация в интернете?
В последние годы Интернет стал самым популярным источником информации. Это вполне закономерно, поскольку поиск данных в Сети удобен, прост и занимает гораздо меньше времени, чем поход в библиотеку, чтение архивов газет или даже просмотр телевизора. В связи с постоянным развитием Интернет-технологий, в обществе сформировалось позитивное общественное мнение о полезности Интернета, а расширение его технических возможностей и аудитории, повлекло за собой появление множества информационных сервисов и ресурсов. Поиск информации через Интернет стал прерогативой не только рядовых пользователей, но и государственных служащих, бизнесменов и коммерческих организаций. Ведь своевременное получение информации способно приносить немалую прибыль и ощутимую пользу. Коммуникация с клиентами и потребителями, доступная реклама перед потенциальной аудиторией, все это открыло массу возможностей как для потребителей, так и для распространителей информации.
Доверяй, но проверяй
Таким образом, рано или поздно перед каждым пользователем Интернета встает один неизбежный вопрос. Можно ли доверять той информации, которая публикуется в Интернете? Осуществлять контроль достоверности информации, полученной в результате поиска, не только можно, но и нужно. Доверять всему, что написано в Сети было бы слишком глупо и наивно, ведь Интернет является зоной свободного доступа, и абсолютно каждый может принимать участие в его наполнении. Рассмотрим традиционные способы проверки полученных через Интернет данных:
1. Проверка фактического материала
Факт выдумать невозможно, ибо его достоверность строго установлена. Любые фактические и статистические данные имеют источник. Проверка точности фактов и приведенных чисел с большой долей вероятности покажет, на какие данные опирается сайт. Идеальным будет наличие ссылок на авторитетные источники вроде агентств сбора статистики или научные институты. Если эта информация не является точной или не соответствует действительности, то и остальной материал также не будет заслуживать доверия.
2. Поиск других источников информации
Сравнение – один из самых эффективных способов поиска истины. Редко одна и та же недостоверная информация публикуется на нескольких сайтах сразу. Поэтому, если одни и те же данные встречаются в Интернете на совершенно разных ресурсах, то им можно доверять. При этом стоит уделить внимание первоначальному источнику информации. К сожалению, не редки случаи, когда все сайты ссылаются на один и тот же недостоверный источник.
3. Установление использования материала другими источниками
Перепечатка и копирование данных с одного сайтам другими сайтами является хорошим знаком, поскольку это означает, что этому источнику доверяют. Чем больше ссылок на исходный материал мы найдем в Интернете, тем выше его авторитет в глазах других ресурсов. Несомненно, это говорит в пользу приведенной информации.
4. Выяснение рейтинга и авторитета сайта
Самый простой и действенный способ убедится в правдивости полученной информации, это ознакомится с репутацией сайта, на котором она размещена. Известные ресурсы обычно заслуживают доверия, поскольку трепетно относятся к своему рейтингу и не станут разменивать его на сомнительные сенсации. Узнать о популярности сайта можно с помощью специальных рейтинговых систем, например через топ «Рамблера» и «Яндекса». Также можно просто вбить название ресурса в любой поисковик и почитать отзывы о нем. Хорошим знаком является наличие у ресурса свидетельства о регистрации СМИ. Онлайн-СМИ несут особую ответственность за любую опубликованную информацию, поэтому стараются избегать непроверенных данных. Кроме того, проверенные данные публикуют официальные сайты, являющиеся первоисточниками.
5. Получение информации об авторе материала
Для того чтобы понять, стоит ли доверять какой-либо статье, можно поискать информацию о статусе и компетентности ее автора. Не лишним будет ознакомиться с другими его работами, комментариями и отзывами читателей. Если автор статьи имеет хороший журналистский опыт, почетную должность или научную степень, шансы на правдивость его доводов прилично возрастают. Кроме того, в Интернете могут быть его блоги, страницы социальной сети и прочая информация, которая поможет составить мнение об авторе.
Поиск – это серьезно
Не менее важен грамотный подход к самому процессу поиска информации. Редкий пользователь точно знает сайты, на которых может получить интересующие его данные. Подавляющее большинство людей использует популярные поисковые сервисы, такие как Google, Yandex, Rambler и Mail. Очень многое зависит от поисковой процедуры и формулировки запроса. Любая поисковая система ищет в своей базе данных из миллиарда страниц те, что соответствуют заданным параметрам. Для этого используется так называемая программа индексации. Она распознает текст, связи, и другое содержание страницы, и хранит это в файлах базы данных так, чтобы страница могла быть найдена по ключевым словам. После того, как пользователь делает поисковый запрос, машина ищет нужное слово в своем индексе. Если бы система искала по всему Интернету, то на ответ ей понадобилось бы несколько дней. Поскольку поиск ведется в индексе, многие результаты могут быть устаревшими. Всем известен пример, когда страница уже не существует, а поисковик все еще ее находит и восстанавливает. При этом многие свежие сайты в поисковый результат не попадают. Поэтому если мы не может найти что-либо в одной поисковой системе, имеет смысл поискать в другой.
Подытоживая, можно сделать следующие выводы. Необходимо четко представлять себе, что мы ищем. Правильно сформулированный запрос сэкономит много времени и усилий, а также позволит найти именно то, что нужно. Стоит доверять официальным сайтам и их пресс-релизам. Также заслуживают доверия информационные агентства, научные институты и их исследования. За опубликованные данные несут ответственность онлайн-СМИ. Отдельную категорию составляют материалы, перепечатанные из реальных источников, но доступные в Интернете. Например, учебники и энциклопедические данные. При этом нужно настороженно относиться к таким ресурсам, как Википедия. Информация, опубликованная в ней, вполне может оказаться недостоверной, поскольку доступ к редактированию статей имеет любой желающий. Это может быть, как опытный профессор, так и обыкновенный школьник. Википедия хороша для расширения кругозора, однако ссылаться на нее в серьезной работе весьма опасно. Тоже самое можно сказать и о блогах. Блоггеры, которых называют «гражданскими журналистами», порой располагают очень интересной информацией, которую нельзя найти даже в СМИ. Но при этом часто никто кроме автора блога не может подтвердить достоверность опубликованной информации. Поэтому использовать блоггерские данные нужно осторожно, проверяя их особенно тщательно. Конечно, речь не идет о президентском блоге или «официальных» блогах компаний.
Руководствуясь правилами элементарной логики, подготовленный пользователь сумеет отличить правду от лжи. Однако даже самый искушенный человек может оказаться обманутым. Засилье многочисленных красиво оформленных сайтов мошенников и желтой прессы способно ввести в заблуждение кого угодно. Крайне важно проверять все важные данные, найденные в Интернете, поскольку последствия использования недостоверной информации могут быть весьма печальными.
Реферат по теме «Поиск информации в Интернете»

Реферат учащегося 10 класса будет полезен как ученикам так и учителю.
Поисковые системы общего назначения. 4
Типология методов поиска. 5
Специализированные поисковые системы. 7
Список литературы. 11
Просмотр содержимого документа
«Реферат по теме «Поиск информации в Интернете» »
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ
РОССИЙСКОЙ ФЕДЕРАЦИИ
МУНИЦИПАЛЬНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ПЕТРЯКСИНСКАЯ СРЕДНЯЯ ОБЩЕОБРАЗОВАТЕЛЬНАЯ ШКОЛА
«Поиск информации в Интернете»
Выполнила: ученица 10 класса
Учитель: Айнетдинова Х. А
Поисковые системы общего назначения 4
Типология методов поиска 5
Специализированные поисковые системы 7
Список литературы 11
Основная задача Интернет – предоставление необходимой информации. Интернет – это информационное пространство, в котором можно отыскать ответ практически на любой интересующий пользователя вопрос. Это огромная глобальная сеть, в которую как информационные ручейки, стекаются потоки более мелких сетей. Любой пользователь, располагающий ПК и соответствующими программами, сможет подключиться к сети, используя её возможности для самых разных целей – проведения досуга, обучения, чтения научных работ, отправки электронной почты и т.д. По различным данным, в 2004 г. количество пользователей глобальной системы Интернет составило от 600 до 900 миллионов человек. Это число продолжает стремительно расти и уже в 2014 г. оно достигло
3 миллиарда человек. Сегодня глобальная сеть превращается в важный социальный и политический фактор современного информационного общества. С развитием Интернет-технологий появился новый гигантский источник информационных ресурсов, доступ к которым является не только относительно дешевым, но и очень быстрым.
Поисковые системы общего назначения
Поисковые системы общего назначения являются базами данных, содержащим тематически сгруппированную информацию об информационных ресурсах Всемирной паутины. Такие поисковые системы позволяют находить Web-страницы по ключевым словам в базе данных или путем поиска в иерархической системе каталогов.
Интерфейс таких поисковых систем общего назначения содержит список разделов каталога и поле поиска. В поле поиска пользователь может ввести ключевые слова для поиска документа, а в каталоге выбрать определенный раздел, что сужает поле поиска и таким образом ускоряет его.
Заполнение баз данных осуществляется с помощью специальных программ-роботов, которые периодически «обходят» Web-серверы Интернета. Программы-роботы читают все встречающиеся документы, выделяют в них ключевые слова и заносят в базу данных, содержащую URL-адреса документов.
Так как информация в Интернете постоянно меняется (создаются новые Web-сайты и страницы, удаляются старые, меняются их URL-адреса и так далее), поисковые роботы не всегда успевают отследить все эти изменения. Информация, хранящаяся в базе данных поисковой системы, может отличаться от реального состояния Интернета, и тогда пользователь в результате поиска может получить адрес уже не существующего или перемещённого документа.
В целях обеспечения большего соответствия между содержанием базы данных поисковой системы и реальным состоянием Интернета большинство поисковых систем разрешают автору нового или перемещенного Web-сайта самому внести информацию в базу данных, заполнив регистрационную анкету. В процессе заполнения анкеты разработчик сайта вносит URL-адрес сайта, его название, краткое описание содержания сайта, а также ключевые слова, по которым легче всего будет найти сайт. Сайты в базе данных ранжируются по количеству их посещений в день, неделю или месяц. Посещаемость сайтов определяется с помощью специальных счетчиков, которые могут быть установлены на сайте. Счетчики фиксирует каждое посещение сайта и передают информацию о количестве посещений на сервер поисковой системы.
Поиск по ключевым словам. Поиск документа в базе данных поисковой системы осуществляется с помощью введения запросов в поле поиска. Простой запрос содержит одно или несколько ключевых слов, которые являются главными для этого документа. Можно также использовать сложные запросы, использующие логические операции, шаблоны и так далее. Через некоторое время после отправки запроса поисковая система вернет аннотированный список URL-адресов документов, в которых были найдены указанные ключевые слова. Для просмотра этого документа в браузере достаточно активизировать указывающую на документ ссылку. Если ключевые слова были выбраны неудачно, то список URL-адресов документов может быть слишком большим (может содержать десятки и даже сотни тысяч ссылок). Для того чтобы уменьшить список, можно в поле поиска ввести дополнительные ключевые слова или воспользоваться каталогом поисковой системы.
Наиболее мощными поисковыми системами общего назначения в русскоязычной части Интернета являются серверы Rambler (http://www.rambler.ru), Апорт (http://www.aport.ru), Яндекс (http://www.yandex.ru), Сервер Yahoo (http://www.yahoo.com).
Типология методов поиска
Более или менее серьезный подход к любой задаче начинается с анализа возможных методов ее решения. Поиск информации в Интернете может быть произведен по нескольким методам, значительно различающимся как по эффективности и качеству поиска, так и по типу извлекаемой информации. В ряде случаев приходится использовать весьма трудоемкие — результат того стоит. Можно выделить следующие основные методы поиска информации в Интернете, которые, в зависимости от целей и задач ищущего, используются по отдельности или в комбинации друг с другом:
1. Непосредственный поиск с использованием гипертекстовых ссылок.
Поскольку все сайты в пространстве WWW фактически оказываются связанными между собой, поиск информации может быть произведен путем последовательного просмотра связанных страниц с помощью браузера. Хотя этот полностью ручной метод поиска выглядит полным анахронизмом в Сети, содержащей более 60 млн. узлов, «ручной» просмотр Web-страниц часто оказывается единственно возможным на заключительных этапах информационного поиска, когда механическое «копание» уступает место более глубокому анализу. Использование каталогов, классифицированных и тематических списков и всевозможных небольших справочников также относится к этому виду поиска.
2. Использование поисковых машин. Сегодня этот метод является одним из основных и фактически единственным при проведении предварительного поиска. Результатом последнего может являться список ресурсов сети, подлежащих детальному рассмотрению.
Как правило, применение поисковых машин основано на использовании ключевых слов, которые передаются поисковым серверам в качестве аргументов поиска: что искать. Если делать все правильно, то формирование списка ключевых слов требует предварительной работы по составлению тезауруса.
3. Поиск с применением специальных средств. Этот полностью автоматизированный метод может оказаться весьма эффективным для проведения первичного поиска. Одна из технологий этого метода основана на применении специализированных программ-спайдеров, которые в автоматическом режиме просматривают Web-страницы, отыскивая на них искомую информацию. Фактически это автоматизированный вариант просмотра с помощью гипертекстовых ссылок, описанный выше (поисковые машины для построения своих индексных таблиц используют похожие методы). Нет нужды говорить, что результаты автоматического поиска обязательно требуют последующей обработки.
Применение данного метода целесообразно, если использование поисковых машин не может дать необходимых результатов (например, в силу нестандартности запроса, который не может быть адекватно задан существующими средствами поисковых машин). В ряде случаев этот метод может быть очень эффективен. Выбор между использованием спайдера или поисковых серверов являет собой вариант классического выбора между применением универсальных или специализированных средств.
Специализированные поисковые системы
С появлением cистем пользовательского поиска от Google (Google Custom Search Engine) специализированные поисковые системы стали появляться как грибы после дождя. В чем же их преимущества перед обычными поисковыми системами? По сути оно только одно, но весьма весомое – если искать информацию по какой-то узкой теме в специализированной поисковой системе, выдача, которая получается в результате запроса, будет гораздо более чистой – не придется отсеивать десятки, а то и сотни ссылок рекламного характера и прочего мусора.
Небольшой список специализированных поисковых систем:
beeMP3 – специализированный поисковые системы по музыке. Можно искать по альбому, исполнителю, песне или всему сразу. У beeMP3 достаточно интересна организована выдача — сразу получаются ссылки на конкретный файл (а не на страницу с ним). Кроме того, наведя курсор мышки на ссылку, можно узнать жанр песни, альбом, год выпуска, битрейт и др.
Tagoo – русскоязычная специализированная поисковая система по музыке
keeperweb.com – специализированная медиа поисковая системы по mp3 музыке, кино, клипам, мелодиям для мобильных телефонов и много другого.
FindSounds – поиск звуковых эффектов и музыкальных сэмплов. В отличие от других мультимедийных поисковых систем, которые ищут песни, радиопередачи и тому подобное, FindSounds ищет только простые звуки и короткие отрывки.
eBdb – поиск электронных книг.
poiskknig.ru – поиск электронных книг, свободно распространяемых в Интернете.
WikiPoisk – поиск по энциклопедиям.
Qwika – специализированныя поисковая система, предназначенная для работы с онлайновой энциклопедией Wikipedia. Является единственной в мире поисковой системой, индексирующей информацию, полученную посредством систем автоматического перевода.
Scirus – поисковая система для ученых, ищет web-страницы с научным содержанием (ищет и русскоязычные сайты): сайты университетов, библиотек и т.д.
ILIGENT – поиск информации на бизнес-сайтах. Для поиска доступны материалы по маркетингу, менеджменту, бухгалтерскому учету, финансам, управлению кадрами предприятия, законодательству. Результаты поиска разделены на 9 типов информации: материалы (статьи), новости, словари, сообщения на форумах, право, рефераты, книги в продаже, платные материалы и мероприятия.
PureVideo – поиск видеофайлов.
Киновед – поиск всего, что связанного с фильмами: отзывов, рецензий и описаний фильмов, информации об актерах кино, биографий, кадров из фильмов, фотографий актеров, постеров, обоев для рабочего стола.
DVD-поиск – специализированная поисковая система фильмов. В базе поиска содержатся базы фильмов самых известных Интернет-магазинов. В результатах поиска выводятся: название фильма, магазин, формат и цена. У некоторых позиций также присутствует небольшая аннотация.
Почему скачут позиции сайта в Яндексе и Google?
В последнее время всё чаще возникают вопросы о том, почему постоянно «скачет» выдача. Почему отличаются позиции сайта в реальной выдаче и в сервисах для съёма позиций? Почему на двух соседних компьютерах выдача может отличаться? Ответы на эти вопросы мы дадим в этой статье.
Мы рассмотрим 2 основные поисковые системы в СНГ-сегменте — Яндекс и Google.
Почему нестабильны позиции в Яндексе?
Непостоянство позиций в Яндексе связано с двумя факторами:
1. Персонализация результатов поиска для каждого пользователя + геозависимость
Если вы видите свой сайт на 5 позиции, а ваш коллега за соседним столом в этот же момент видит сайт на 9 позиции, это персонализация выдачи.
Ещё больше позиции могут отличаться у пользователей, которые находятся в разных городах (по геозависимым запросам). Если владелец сайта находится в Москве, а оптимизатор — в Долгопрудном, то по одному и тому же запросу они одновременно могут видеть совершенно разную выдачу.
2. Рандомизация результатов поиска («Многорукий бандит»)
Если в 10 часов утра вы видите свой сайт на 5 позиции, а в 12 дня на 9 — это «Многорукий бандит» (рандомизирующий алгоритм).
На момент запуска «Бандит» перемешивал выдачу сугубо во время апдейтов: после одного апдейта сайт мог вылететь из ТОПа, после следующего вернуться в ТОП, а затем снова вылететь и т. д. Со временем скачки участились — позиции начали меняться независимо от апдейтов раз в 2-3 дня, а после — ежедневно. Сейчас по многим запросам выдача меняется постоянно в течение дня, то есть в живом режиме.
Рассмотрим подробнее каждую из причин.
Персонализированная выдача
Изучая местоположение и поведение своих пользователей, Яндекс старается сделать выдачу для каждого пользователя максимально точной. При формировании персонализированной выдачи Яндекс отслеживает следующие параметры:
- Геозависимость — Яндекс учитывает местоположение своего пользователя;
- История запросов — ваша история запросов влияет на ранжирование в Яндексе. В некоторых случаях достаточно нескольких запросов, чтобы выдача начала формироваться по-другому;
- История переходов — сайты, на которые вы чаще всего заходите из Яндекса, также могут влиять на ранжирование.
В результате два пользователя с разными интересами по одному и тому же запросу могут видеть разные результаты поиска.
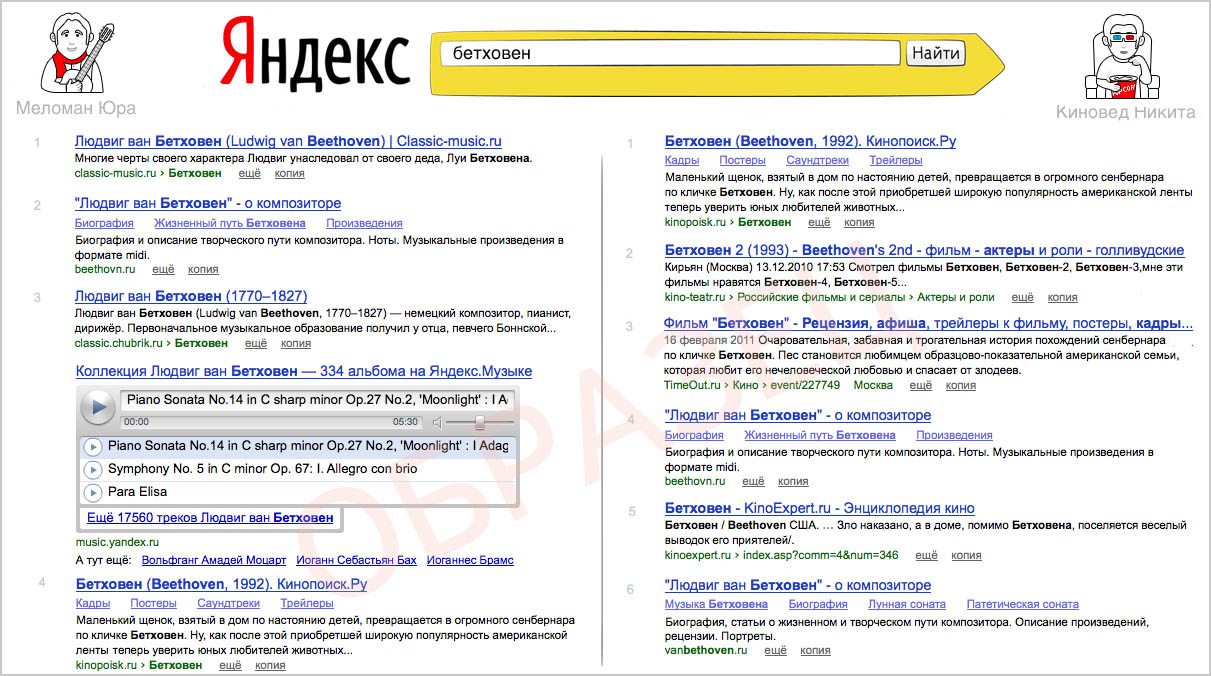
Как определить, что выдача по запросу персонализирована?
Если ваша выдача не совпадает с выдачей по тому же запросу за соседним компьютером, скорее всего, у вас персонализированная выдача. Это можно проверить в настройках результатов поиска.
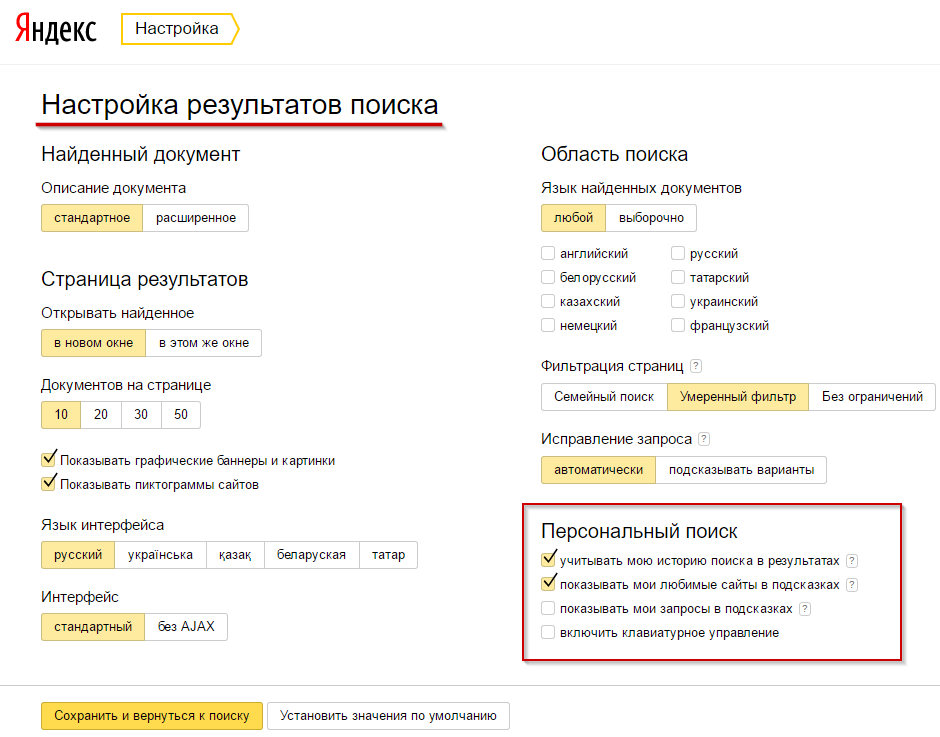
Галочки, которые стоят в меню «Персональный поиск», говорят о том, что сейчас включена персонализированная выдача.
Как убрать персонализацию в своём поиске?
Для начала нужно убрать галочки в настройках «Персонального поиска», но даже так выдача будет формироваться с учётом вашего местоположения.
Самый надёжный способ — замерять позиции в режиме «Инкогнито», предварительно указав интересующий регион в настройках.
Как включить режим инкогнито?
Браузеры Chrome и Opera – Ctrl + Shift + N
Браузеры FireFox и Internet Explorer – Ctrl + Shift + P
Персонализированная выдача делает выдачу уникальной для каждого пользователя Яндекса. Иногда возникают ситуации, когда пользователь замеряет позиции в сервисе для съёма позиций и сравнивает их с нынешними у себя в компьютере, и они отличаются. Это последствие персонализированной выдачи. Выдача может отличаться у людей за двумя соседними компьютерами, так как она формируется из персональных предпочтений пользователя.
Детальнее о персонализированной выдаче можно узнать на сайте Яндекса:
Запуск персонализированной выдачи в Яндексе — платформа «Калининград»;
Улучшение персонализированной выдачи — алгоритм «Дублин»;
Поиск с учётом региона.
Также рекомендуем интервью с Денисом Рогачевским (менеджер поисковых проектов Яндекса):
«Многорукий бандит»
«Многорукий бандит» — это специальный алгоритм, который рандомно подмешивает в ТОП новые сайты, чтобы дать им возможность накопить ПФ. Впервые действие алгоритма было отмечено оптимизаторами летом 2015 года.
Если позиции вашего старого и трастового сайта, который годами стабильно держался в ТОПе, со второй половины 2015 года начали рандомно меняться, скорее всего, вы стали жертвой «Многорукого бандита».
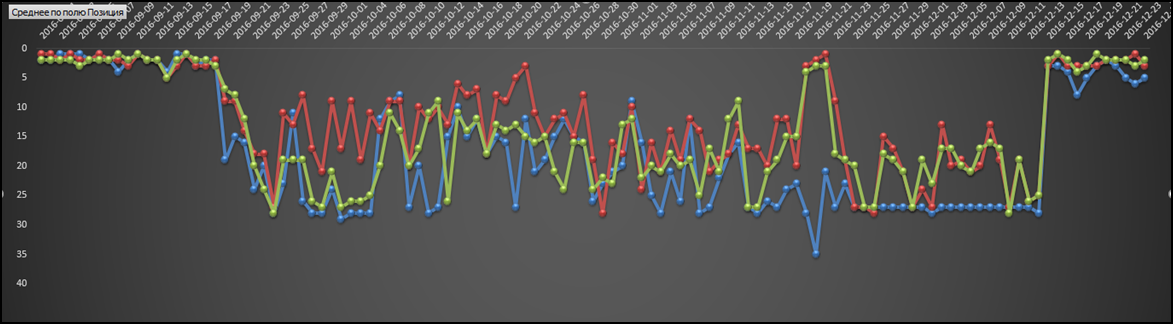
На скриншоте показаны скачки по 3 запросам, которые изначально находились в ТОПе, но попали под влияние «Многорукого бандита», и их позиции начали скакать. Такие скачки длились 4 месяца.
Как определить «Многорукого бандита»?
Если позиции вашего сайта начинают скакать между апдейтами, то, скорее всего, вы попали под влияние алгоритма. Более того, выдача может меняться и в течение дня. Это может привести к тому, что позиции, снятые в 9:00 и в 10:00 того же дня, могут не совпадать.
Что делать?
Если ваш сайт попал под влияние «многоруких», то вам остаётся только ждать. Со временем позиции должны вернуться.
Из-за «Многорукого бандита» выдача может обновляться постоянно, а не только в период апдейтов. В результате ваш сайт в течение дня может занимать разные позиции по одному и тому же запросу.
Детальнее об алгоритме «Многорукий бандит» можно узнать из блога и доклада Яндекса:
Также рекомендуем ознакомиться с видео по этой теме от Екатерины Гладких (Яндекс) «Практика детерминированного хаоса»:
Итог по Яндексу
Выдача в Яндексе у разных пользователей может отличаться, а также меняться в течение дня. Иногда это очень сильно влияет на поисковый трафик. Если позиции и трафик вашего сайта в Яндексе постоянно скачут, нужно немедленно определить причину происходящего — из-за общей нестабильности выдачи есть риски не заметить тревожных симптомов фильтров и санкций. Вы можете диагностировать причины скачков самостоятельно по этой инструкции или обратиться к нам, заполнив форму «Записаться к SEO-доктору».
Почему меняется выдача Google?
Выдача Google также может меняться и отличаться от той, которую вам показывает сервис для съёма позиций или соседний компьютер. Причина в том, что Google, как и Яндекс, использует персонализированную выдачу, запущенную в 2009 году. Информацию об этом представители Google разместили в своём блоге.

Как это работает?
С тех пор алгоритм развивался, стал сложнее и начал учитывать новые данные. При формировании выдачи Google учитывает, вошли вы в аккаунт Google или нет. Если вы вошли в аккаунт, то будут учитываться следующие показатели:
- Местоположение — где вы сейчас находитесь;
- Устройство, с которого вы заходите – это может быть смартфон или планшет, выдача у них будет разной;
- История поиска — будет учитывать историю поиска и то, на что вы кликали в результатах выдачи;
- Google Calendar — если вы пользуетесь календарём, та данные в нём могут также влиять на выдачу. К примеру, если у вас в календаре запланирован авиарейс, то при поиске номера рейса будет высвечиваться информация о запланированном рейсе;
- Google+ — в результатах выдачи могут отображаться публикации друзей из Google+, чаще всего они будут в выдаче внизу, но в некоторых случаях могут быть и выше;
- История визитов — если вы часто посещаете один и тот же сайт, он может подмешиваться в выдачу и ранжироваться выше;
- Закладки — сайты, добавленные в закладки, также могут учитываться при формировании выдачи.
При формировании выдачи Google без входа в аккаунт Google будут учитываться местоположение, устройство, история поиска и история визитов.
Как определить, персонализирована ли ваша выдача в Google?
Определить персонализацию выдачи можно примерно так же, как и в Яндексе. В настройках поиска Google есть кнопка в правом нижнем углу.
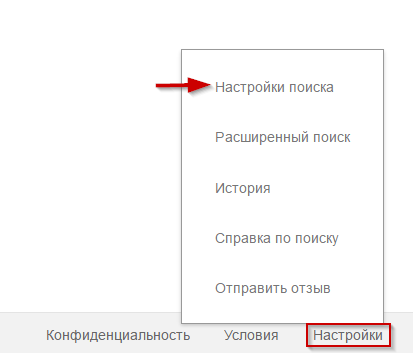
Нужно найти пункт «Персональные результаты».

Детальнее о персонализированной выдаче Google:
Для ознакомления рекомендуем статью Рэнда Фишкина «Elements of Personalization & How to Perform Better in Personalized Search» и видео на ту же тему:
Постскриптум
Нестабильность выдачи в Яндексе и Google усложняет жизнь как оптимизаторам, так и владельцам сайтов. Но нужно понимать, что для разработчиков алгоритмов в приоритете всегда интересы пользователей. Если вы всё ещё делаете ставку на позиции, пора оставить надежды на то, что всё стабилизируется, и начать приспосабливаться к действительности. О том, как это сделать, мы расскажем в следующих статьях.
Не подумайте, что больше не нужно проверять позиции сайта. Чтобы держать руку на пульсе и вовремя замечать тенденции к снижению или росту, позиции нужно обязательно проверять. Просто раньше это достаточно было делать после апдейтов или раз в неделю, сейчас же стоит мониторить выдачу ежедневно.

Всегда знал, что моя работа будет связана с интернетом и компьютером. Начал самостоятельно учить HTML и пробовать себя в верстке. HTML давался легко, но верстать сайты было скучно. Тогда я и узнал о SEO.
С отличием завершил мастер-класс по обучению и управлению персоналом. Сдал письменный тест по английскому языку в Лондонской школе на 98%. Написал более десятка развивающих статей по SEО.
Работаю SEO-специалистом в компании SiteClinic, пишу статьи для блога. В свободное время хожу в походы.