
Как найти архив сайта в интернете?
Найти удаленный сайт — легко с помощью web.archive.org
Как найти информацию в Интернете, которую не отображают такие продвинутые поисковые системы как Google или Яндекс? Можно ли найти сайты, которые когда-то существовали в сети, но уже не работают, удалены или же заменены новыми? На эти вопросы мы постараемся дать ответ в этой статье.
Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.

Главная страница сайта Archive.org
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».

Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).

Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.
Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Как скачать сайт из веб архива
Если вы желаете восстановить сайт из веб-архива, то вам в этом поможет программа Web Archive Downloader 6.0
9 способов найти удаленный сайт или страницу

Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
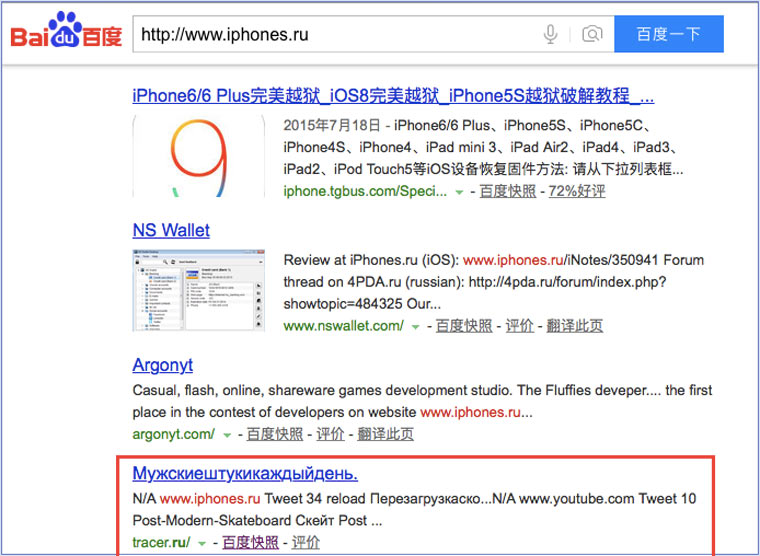
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
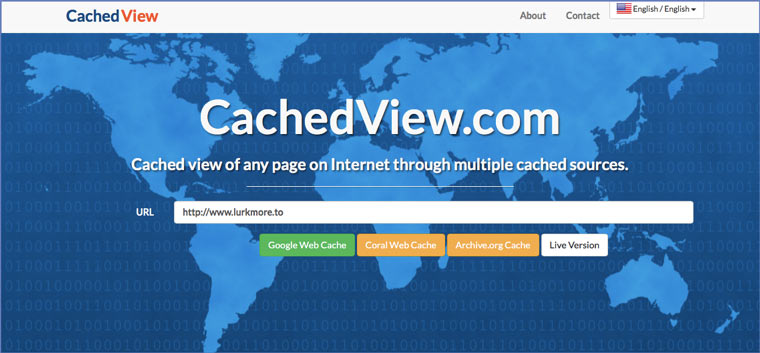
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
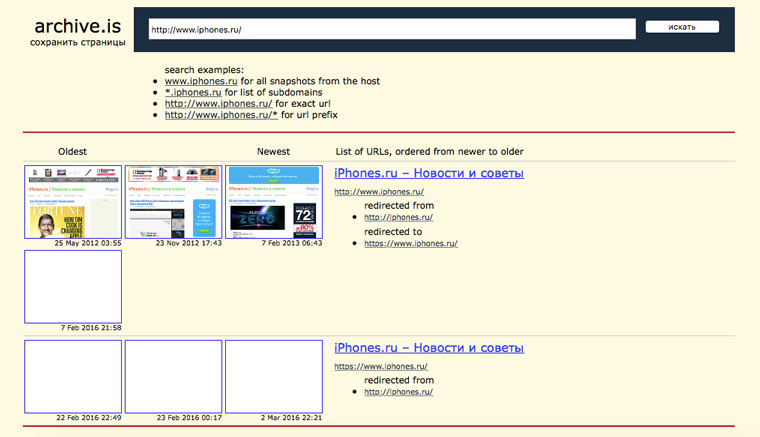
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
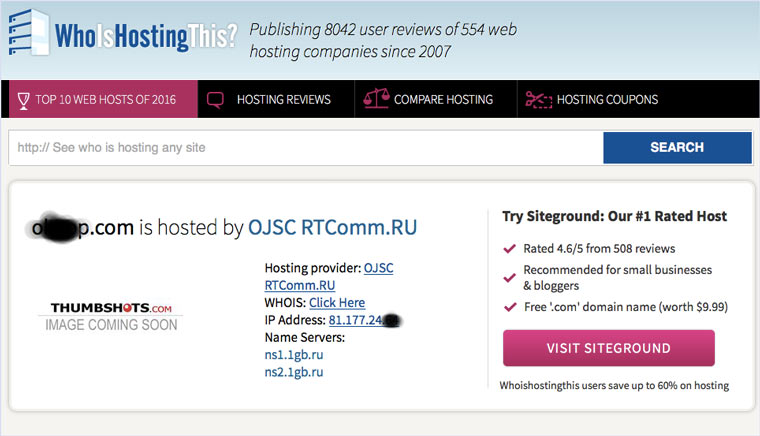
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com: 
Веб-архив сайта

Еще не зарегистрированы?
Создание и наполнение онлайн-ресурса — это многоэтапный системный процесс. Контент фирменного сайта, интернет-магазина, лэндинга или портала должен постоянно обновляться с учетом целей и задач компании, изменений предпочтений целевой аудитории и алгоритмов поисковых систем. Но иногда старые тексты могут пригодиться, и тогда их можно найти на веб-архивах.

Что такое веб-архив
Веб-архив (web archive, internet archive) — это онлайн-платформа Wayback Machine, созданная в 1996 году. Здесь хранятся копии контента сайтов, интернет-магазинов, блогов, информационных и развлекательных порталов и других интернет-ресурсов, которые разрешены для сохранения. Это бесплатная онлайн-библиотека web.archive.org, где можно найти разные версии всех веб-ресурсов и просмотреть, как выглядел их контент, сохраненный на дату посещения сайта роботом сервиса.
Со времени создания веб-архива, здесь накопилось и на данный момент хранится больше 330 миллиардов файлов:
- интернет-страниц;
- аудио;
- видео;
- электронных книг и пр.

Зачем нужен web archive и как его можно использовать
Веб-архивирование нужно для того, чтобы можно было восстановить важную утерянную информацию с сайта, которая может не сохраниться из-за технических проблем или повреждения вирусом.

Например, владелец сайта создал его и наполнил описанием продукции, полезными статьями и изображениями по тематике. Через время веб-ресурс был обновлен и тексты заменены на новые. А еще через время понадобились именно старые тексты. В таких случаях и нужен открытый интернет-архив, в котором можно найти десятки сохраненных версий сайта на разные даты.
- Возможность восстановления собственного контента в случае повреждения или удаления старых текстов и изображений.
- Просмотр старых файлов на других работающих веб-сайтах.
- Анализ изменений наполнения онлайн-ресурсов (собственных и конкурентных).

Сохранение авторского контента — это важная функция. Намного проще корректировать уже имеющиеся тексты, чем писать новые с нуля. Можно сделать рерайт (переписывание текста другим словами с сохранением смысла и структуры). Особенности использования резервных копий приведены в Табл. 1.
Табл. 1. Для каких целей можно использовать более ранний контент
| Цели | Особенности применения |
| Восстановление сайта | Бывают случаи непоправимого повреждения онлайн-ресурса — из-за вирусов, хакерских атак. Если не было проведено резервное копирование на своем хостинге, то можно будет найти свои тексты в веб-архиве |
| Наполнение сайта по похожей тематике | Старый экспертный текст по своей тематике может понадобиться при создании лэндинга, вспомогательного онлайн-ресурса. Если тексты неуникальны, их нужно рерайтить |
| Ведение блога | Для привлечения трафика на профильный сайт нужно вести блог с текстами узкой тематики. Это могут быть советы по выбору товаров, использованию продукции и другой контент. Для написания таких текстов может потребоваться информация со старых копий веб-ресурса |
| Публикации на странице в социальных сетях | Бизнес-аккаунт в соцсетях помогает поднять узнаваемость бренда и компании, привлечь новых покупателей, расширить рынки сбыта. Для постов в социальных сетях можно использовать тексты, которые ранее были опубликованы на сайте (если они не дублируются с новыми) |

Как просмотреть старые версии сайтов на Wayback Machine
Если вам необходимо найти старую версию страниц какого-либо веб сайта, выполните следующие действия:
- Наберите в поисковой строке адрес https://web.archive.org/.
- С главной страницы архива сайтов перейдите по ссылке на нужный раздел (файлы, видео, изображения и пр.), укажите адрес домена и нажмите «BROWSE HISTORY».
- Во временной шкале будут отображены все копии сайтов. Словно с помощью машины времени, здесь можно найти любую созданную ранее архивную копию и даже скачать ее при помощи специальных инструментов.
- В открывшемся календаре можно выбрать дату, отмеченную зеленым или голубым кружком (диаметр этого кружка зависит от числа обращений робота сервиса к онлайн-проекту в указанный день). Зеленым кружком обозначены редиректы.

Важно! Если веб-страницу через некоторое время не удается просмотреть, это может быть вызвано несколькими причинами:
- Правообладатель обратился на платформу архива интернета с требованием удалить копии.
- Сам веб-проект был закрыт из-за нарушения авторских прав и закона об использовании интеллектуальной собственности.
- Разработчики закрыли страницы своего онлайн-ресурса от индексации роботами поисковых систем.
Если вы хотите посмотреть, как выглядел веб-сайт, но на сохраненной копии нет изображений или других элементов дизайна (иногда они не сохраняются), нужно открыть другую версию, которую веб-архив сохранил в другой день.

Как добавить современную версию сайта в веб-архив Wayback Machineи выполнить другие действия
Онлайн-платформа по веб-архивированию сайтов предоставляет множество возможностей разработчикам и владельцам ресурсов (Табл. 2).
Табл. 2. Как работать с веб-архивом
| Возможности | Особенности выполнения |
| Сохранение нужной версии сайта на платформе интернет-архива | Нужно самостоятельно инициировать сохранение. В разделе платформы «Save Page Now» нужно забить домен онлайн-ресурса и нажать «Save page». Такую процедуру рекомендуется повторять каждый раз, когда в контент были внесены исправления или дополнения |
| Запрет на добавление интернет-ресурса в память веб-архива | Для запрета добавления нужно прописать это в файле robots.txt. В панелях хостеров есть корневой каталог, в котором предусмотрена возможность редактирования файлов. При введении кода User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: / файл будет скрыт от копирования. При введении такого кода из веб-архива удаляется и текущая версия сайта и не осуществляется системное копирование (до тех пор, пока в файле robots.txt есть такие настройки или пока не закончится срок регистрации домена) |
| Восстановление веб-сайта из интернет-архива | Если сайт был поврежден вирусами или есть другие технические проблемы, из-за которых контент был нарушен, можно восстановить файлы из онлайн-хранилища. Для этого применяются специальные сервисы. Есть платные и бесплатные варианты, которые выбираются с учетом количества страниц для восстановления |

Уникальный контент из веб-архива
Многие коммерческие сайты через некоторое время существования закрываются. Если на них был опубликован полезный контент (экспертные статьи, аналитические обзоры и другая важная информация), то после закрытия первоисточника они могут быть востребованными. То есть, сайт уже не работает и ранее написанные статьи могут использоваться на информационных порталах (если они уникальны).
Веб-архив является очень полезным сервисом, который может пригодиться в различных ситуациях. Быстрое восстановление потерянных данных может значительно сэкономить время и финансы, если сайт подвергнется хакерской атаке или же перестанет работать из-за серьезной технической проблемы. Веб-архив дает возможность не только просматривать старые версии своего сайта, но и анализировать контент конкурентов, сохраненный в разные периоды времени.
ВЕБ-архив

2021-06-29 • 9 мин читать
WebArchive — огромная бесплатная библиотека, в которой хранятся web-архивы сайтов — миллиарды страниц, в том числе те, которых уже нет в Яндекс и Google. Это живая история интернета, поскольку в Web-архиве можно посмотреть старую версию сайта, узнать, какой контент размещался на интересующем домене и даже восстановить удаленные документы.
Что такое веб-архив?
Организатор и идейный вдохновитель веб-архива сайтов — американец Брюстер Кейл. Internet Archive («Архив интернета») — некоммерческий проект, его цель — сохранить мировое культурное и интеллектуальное наследие. По данным Википедии, этот сервис был создан в 1996 году. Во всемирном архиве интернета хранятся литературные произведения, видеозаписи, изображения, которые свободно публикуются в Сети. Это один из разделов огромного сервиса archive.org.
Боты постоянно сканируют всемирный интернет и пополняют библиотеку. Роботам помогают живые сотрудники и партнеры. Добавить копии страничек в веб-архив интернета может любой желающий. Конечно, в библиотеке невозможно найти абсолютно все страницы, которые когда-то были созданы. Но их там очень много — более 580 миллиардов.
Просмотреть архив «машины времени» («Wayback Machine» — второе название web-архива сайтов) можно бесплатно. При этом пользователям предлагают перейти по ссылке «Пожертвовать» и перевести создателям уникального сервиса посильную сумму.
Возможности сервиса
Для вебмастера и SEO-специалиста бесплатные всемирные архивы открывают ряд полезных возможностей.
- Если планируется купить домен или интернет-проект, важно посмотреть историю сайта. В ней могут быть «криминальные» эпизоды. Например, распространение пиратских видеозаписей, продажа запрещенных товаров или адалт-контент. «Темное прошлое» может негативно сказаться на продвижении проекта в поисковых системах.
- Архив веб-страниц поможет при выборе дроп-домена. В сервисе можно посмотреть бесплатно, какой проект на нем располагался (коммерческий, информационный) и как он выглядел.
- Можно узнать историю конкурентов. Сравнивая архивы сайтов с их современной версией, легко понять, как менялась ниша, как трансформировались проекты.
- Есть возможность проследить и проанализировать изменения на собственном сайте и даже восстановить измененный по ошибке URL.
- С помощью дополнительных сервисов можно восстановить удаленный ресурс или отдельные страницы.
- А также найти контент по интересующей теме, которого уже нет в глобальной сети.
Как посмотреть архивные страницы?
Откройте в браузере https://web.archive.org/. В строке для поиска укажите URL главной или любой другой страницы нужного сайта.
Сервис покажет график сохранений и календарь, в котором обведены даты сканирований. Эти даты не связаны с датами обновления контента. Боты работают по собственному графику.
Если кликнуть на нужный год и дату, сервис покажет web-версию старых страниц. Обычно сохраняется не весь контент, часть документов недоступна, отображаются не все фотографии и картинки. Часть ссылок кликабельны, можно погулять по интернет-площадке, перейти в другие разделы.
Если вы не знаете точный адрес нужного ресурса или хотите изучить целую нишу, нужно набрать в поисковой строке главные ключевые слова. Архив бесплатно найдет сайты нужной тематики. Перейдите по ссылкам этого списка и изучайте историю интересующего проекта.
Существует приложение Wayback Machine («Машина времени») для iOS и Android. Приложение скачивают на мобильное устройство. В нем заложен тот же функционал, что и в десктопной версии.
Как добавить страницу в сервис?
Боты обходят интернет по собственному графику. Не все проекты попадают в историю «Машины времени». Молодые площадки с небольшим трафиком редко оказываются в библиотеке. А если и попадают туда, то частота сканирований очень низкая — раз в несколько месяцев.
Сохранять копии сайта в WebArchive можно самостоятельно. Для этого нужно открыть сервис, найти поле «Сохранить страницу» и добавить туда URL. Снимки появятся в библиотеке через пару минут.
Эту операцию можно периодически повторять.
В будущем эти копии будут полезны, чтобы отслеживать изменения в дизайне, структуре, контенте. Если страницы будут по ошибке удалены, а бэкапы не делались или были утеряны, архивные снимки помогут восстановить документ.
Как удалить копии страниц своего проекта?
Не всем и не всегда хочется выкладывать историю своей веб-площадки на всеобщее обозрение. Например, на сайте могла быть выложена ошибочная, некорректная или противозаконная информация. Даже если удалить страницу или файл, они сохранятся в библиотеке.
Архивом страниц могут заинтересоваться конкуренты и недоброжелатели. Поэтому многим хочется удалить копии веб-документов из сервиса.
Раньше вебмастера вписывали в robots.txt запрещающую директиву для ботов. Но сейчас это уже не работает.
Убрать страницы из библиотеки можно только через саппорт. Для этого нужно написать письмо на info@archive.org. Писать нужно по-английски, с указанием реальных имени, фамилии, физического адреса. Чтобы подтвердить, что вы владелец ресурса, отправлять письмо лучшего с почтового ящика, указанного на сайте. Еще один способ подтвердить свои права — написать через регистратора домена или через хостинг. Иногда саппорт просит прислать копию паспорта.
Через поддержку можно навсегда запретить делать копии своего проекта.
Как восстановить сайт из архива?
Если вы сами загрузили копию страницы, ее можно найти в своем аккаунте в разделе «Мой архив».
Чтобы скачать страницу, найдите ее в списке, кликните по виджету справа и сохраните документ в виде html-файла.
С чужими сайтами действуют примерно так же: открывают копию в архиве, через панель разработчика копируют html-код, стили, изображения.
Файлы заливаются по FTP в корневую директорию домена на хостинге.
Но ручной способ слишком долгий и трудоемкий. Автоматизировать процесс можно через платные онлайн сервисы: Archivarix, waybackmachinedownloader, r-tools, rush-analytics и другие. Здесь можно не только скачать файлы, но и оптимизировать их: убрать битые ссылки, неработающие скрипты и так далее. Некоторые сервисы умеют импортировать файлы в WordPress.
Другие полезные опции
WebArchive умеет не только сохранять копии и показывать старую версию страниц сайта. Здесь есть несколько полезных инструментов аналитики.
- Сводка. Сервис показывает, какие данные содержит сайт: сколько на нем текстов, изображений, приложений. Можно открыть и просмотреть список всех URL.
- Изменения. Инструмент поможет выявить изменения в URL-адресах. Для этого надо выбрать архивы на разные даты и сравнить старшие копии с младшими. Изменения будут выделены цветом.
- Карта сайта. Группирует данные по годам и строит карту в виде круговой диаграммы для каждого года.
В центре диаграммы корень сайта, а кольца — это разделы и страницы. Диаграмма кликабельна, она позволяет перейти на копию нужного URL.
Читайте на Askusers
Как быстро и правильно провести A/B-тестирование в маркетинге и SEO? Что можно тестировать, какие инструменты использовать и как замерять результат?
Что такое коммерческие факторы ранжирования, как они влияют на трафик и конверсию и как их улучшить?
Если страницы выпали из индекса поисковых систем — это тревожный признак, надо срочно искать причину. Подробный алгоритм проверки.
8 способов найти удаленный сайт или страницу

Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кеша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.iphones.ru/
Где http://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет
К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
Что делать, если вообще ничего не помогло