
Как посмотреть архив сайта в интернете?
Как посмотреть на сайт в прошлом: инструмент + способ восстановления

Сервис, который может показать, как выглядели сайты в прошлом, напоминает своеобразную машину времени в интернете. С его помощью можно перенестись на год, два или двадцать лет назад и увидеть, какими ресурсы были тогда. Зачем может понадобиться эта информация и как воспользоваться данным сервисом?
Для чего нужно искать старые версии сайтов
Причины, по которым может быть необходимо посмотреть сайт в прошлом времени, могут быть абсолютно разными. Часто это желание погрузиться в приятную ностальгию. Например, посмотреть, как раньше выглядели популярные площадки и соцсети. Или же посмотреть, как выглядел собственный сайт несколько лет назад. К счастью, существует инструмент, который позволяет это сделать, даже если сам ресурс уже давно не доступен.
Как это возможно? Если сайт существует в интернете хотя бы пару дней, он попадает в веб-архив. Инструмент сохраняет его код, благодаря чему, можно увидеть, как он выглядел даже много лет назад.
Причины, по которым возникает необходимость посмотреть порталы в прошлом времени:
- Отслеживание истории изменений. Такая потребность может возникать у копирайтеров или журналистов для подготовки нового контента. Также это может быть нужно для анализа конкурентов: можно проследить путь их развития и увидеть допущенные ошибки.
- Восстановление ресурса. Если пользователь забыл продлить домен или не сделал бэкап, веб-архив будет отличным вариантом восстановления.
- Поиск уникального контента. Если площадка больше не доступна, её контент становится уникальным. Можно использовать его полностью или частично, предварительно проверив уникальность.
- Увидеть необходимый контент, если страница уже недоступна. Например, пользователь добавил площадку в закладки, а через время оказалось, что её больше нет. Тогда посмотреть её содержимое можно только с помощью веб-архива.
Как узнать прошлое веб-ресурса с помощью archive.org
Чтобы узнать, как выглядел конкретный веб-ресурс ранее, можно воспользоваться сайтом для просмотра страниц в прошлом – a rchive.org. Для этого нужно выполнить следующее:
- Пройти по ссылке https://archive.org/.
- Ввести URL-адрес и нажать кнопку «Go».

- Выбрать интересующий период времени. Затем с помощью календаря найти нужную дату, навести на нее курсор мыши и выбрать время сохранения копии (в списке может быть как одна, так и несколько ссылок).

После этого откроется главная страница в том виде, какой она была в выбранный период.

Учитывайте, что кликабельными в календаре являются только дни, помеченные синим или зеленым цветом. Посмотреть, как выглядел сайт в даты без подсветки, не получится.
Если это страница Вконтакте
Аналогичным образом можно узнать содержимое страницы ВКонтакте. Достаточно указать на нее ссылку в соответствующем поле.
По сравнению с новостными или другими веб-ресурсами здесь будет меньше подсвеченных дат с сохранённым содержимым. Количество дат зависит от популярности страницы: у обычных пользователей их будет немного, в то время как у известных медиа-личностей – на порядок больше.

Дальнейшие действия такие же: надо выбрать любую из подсвеченных дат и перейти по кликабельной ссылке. В этой же вкладке откроется страница в ВКонтакте с актуальным на тот момент содержимым.
Как выглядели культовые сайты раньше
Для примера посмотрим, как выглядели популярные ресурсы раньше, а именно Яндекс, Google, YouTube, Википедия и VK. Все из них с течением времени претерпели кардинальные изменения в дизайне.
Поисковик Яндекс
Поисковую систему Яндекс официально анонсировали 23 сентября 1997 года. С тех прошло более 20 лет, и сегодня это одна из самых популярных поисковых систем в мире.
В веб-архиве первая сохраненная копия датируется 6 декабря 1998 года.

На тот момент выглядел Яндекс вот так:

Поисковик Google
Поисковая система Google была основа чуть позже – в 1998 году. Сейчас это самая популярная поисковая система в мире.
Первые сохраненные копии появились в веб-архиве в конце 1998 года. Например, 2 декабря Гугл выглядел вот так:

YouTube
Youtube начал свою работу в феврале 2005 года. Первые сохраненные в веб-архиве копии появились в конце апреля 2005 года. На то время сервис имел минималистичный дизайн, и видно, что он являлся не более, чем видеохостингом:

Википедия
Википедия появилась 15 января 2001 года. Сегодня она является наиболее крупным и популярным справочником в интернете и содержит более 40 миллионов статей, которые доступны на 301 языке.
В веб-архиве первая сохраненная копия Википедии датируется 27 июля 2001 года:

ВКонтакте
Популярная в России и других странах социальная сеть ВКонтакте была создана 10 октября 2006 года.
В веб-архиве первая сохраненная копия сайта датируется 8 ноября 2006 года. На нём видно, что сайт изначально был ориентирован на студентов и выпускников.

Можно ли восстановить сайт из вебархива?
При потере данных, восстановить свой сайт можно с помощью сайта https://webarchiveorg.ru/. Для этого нужно:
- ввести URL-адрес;
- выбрать нужный год, месяц и число;
- нажать кнопку «Восстановить сайт».

Услуга является платной, поэтому перед восстановлением рекомендуется ознакомиться с тарифами. Точная стоимость зависит от количества сайтов и его страниц.
Выводы
С помощью веб-архива можно посмотреть, какой дизайн и контент были у сайтов раньше, что может быть необходимо для восстановления данных, анализа конкурентов, поиска интересного контента с исчезнувших ресурсов или просто ради интереса.
Веб-архив сайта

Еще не зарегистрированы?
Создание и наполнение онлайн-ресурса — это многоэтапный системный процесс. Контент фирменного сайта, интернет-магазина, лэндинга или портала должен постоянно обновляться с учетом целей и задач компании, изменений предпочтений целевой аудитории и алгоритмов поисковых систем. Но иногда старые тексты могут пригодиться, и тогда их можно найти на веб-архивах.

Что такое веб-архив
Веб-архив (web archive, internet archive) — это онлайн-платформа Wayback Machine, созданная в 1996 году. Здесь хранятся копии контента сайтов, интернет-магазинов, блогов, информационных и развлекательных порталов и других интернет-ресурсов, которые разрешены для сохранения. Это бесплатная онлайн-библиотека web.archive.org, где можно найти разные версии всех веб-ресурсов и просмотреть, как выглядел их контент, сохраненный на дату посещения сайта роботом сервиса.
Со времени создания веб-архива, здесь накопилось и на данный момент хранится больше 330 миллиардов файлов:
- интернет-страниц;
- аудио;
- видео;
- электронных книг и пр.

Зачем нужен web archive и как его можно использовать
Веб-архивирование нужно для того, чтобы можно было восстановить важную утерянную информацию с сайта, которая может не сохраниться из-за технических проблем или повреждения вирусом.

Например, владелец сайта создал его и наполнил описанием продукции, полезными статьями и изображениями по тематике. Через время веб-ресурс был обновлен и тексты заменены на новые. А еще через время понадобились именно старые тексты. В таких случаях и нужен открытый интернет-архив, в котором можно найти десятки сохраненных версий сайта на разные даты.
- Возможность восстановления собственного контента в случае повреждения или удаления старых текстов и изображений.
- Просмотр старых файлов на других работающих веб-сайтах.
- Анализ изменений наполнения онлайн-ресурсов (собственных и конкурентных).

Сохранение авторского контента — это важная функция. Намного проще корректировать уже имеющиеся тексты, чем писать новые с нуля. Можно сделать рерайт (переписывание текста другим словами с сохранением смысла и структуры). Особенности использования резервных копий приведены в Табл. 1.
Табл. 1. Для каких целей можно использовать более ранний контент
| Цели | Особенности применения |
| Восстановление сайта | Бывают случаи непоправимого повреждения онлайн-ресурса — из-за вирусов, хакерских атак. Если не было проведено резервное копирование на своем хостинге, то можно будет найти свои тексты в веб-архиве |
| Наполнение сайта по похожей тематике | Старый экспертный текст по своей тематике может понадобиться при создании лэндинга, вспомогательного онлайн-ресурса. Если тексты неуникальны, их нужно рерайтить |
| Ведение блога | Для привлечения трафика на профильный сайт нужно вести блог с текстами узкой тематики. Это могут быть советы по выбору товаров, использованию продукции и другой контент. Для написания таких текстов может потребоваться информация со старых копий веб-ресурса |
| Публикации на странице в социальных сетях | Бизнес-аккаунт в соцсетях помогает поднять узнаваемость бренда и компании, привлечь новых покупателей, расширить рынки сбыта. Для постов в социальных сетях можно использовать тексты, которые ранее были опубликованы на сайте (если они не дублируются с новыми) |

Как просмотреть старые версии сайтов на Wayback Machine
Если вам необходимо найти старую версию страниц какого-либо веб сайта, выполните следующие действия:
- Наберите в поисковой строке адрес https://web.archive.org/.
- С главной страницы архива сайтов перейдите по ссылке на нужный раздел (файлы, видео, изображения и пр.), укажите адрес домена и нажмите «BROWSE HISTORY».
- Во временной шкале будут отображены все копии сайтов. Словно с помощью машины времени, здесь можно найти любую созданную ранее архивную копию и даже скачать ее при помощи специальных инструментов.
- В открывшемся календаре можно выбрать дату, отмеченную зеленым или голубым кружком (диаметр этого кружка зависит от числа обращений робота сервиса к онлайн-проекту в указанный день). Зеленым кружком обозначены редиректы.

Важно! Если веб-страницу через некоторое время не удается просмотреть, это может быть вызвано несколькими причинами:
- Правообладатель обратился на платформу архива интернета с требованием удалить копии.
- Сам веб-проект был закрыт из-за нарушения авторских прав и закона об использовании интеллектуальной собственности.
- Разработчики закрыли страницы своего онлайн-ресурса от индексации роботами поисковых систем.
Если вы хотите посмотреть, как выглядел веб-сайт, но на сохраненной копии нет изображений или других элементов дизайна (иногда они не сохраняются), нужно открыть другую версию, которую веб-архив сохранил в другой день.

Как добавить современную версию сайта в веб-архив Wayback Machineи выполнить другие действия
Онлайн-платформа по веб-архивированию сайтов предоставляет множество возможностей разработчикам и владельцам ресурсов (Табл. 2).
Табл. 2. Как работать с веб-архивом
| Возможности | Особенности выполнения |
| Сохранение нужной версии сайта на платформе интернет-архива | Нужно самостоятельно инициировать сохранение. В разделе платформы «Save Page Now» нужно забить домен онлайн-ресурса и нажать «Save page». Такую процедуру рекомендуется повторять каждый раз, когда в контент были внесены исправления или дополнения |
| Запрет на добавление интернет-ресурса в память веб-архива | Для запрета добавления нужно прописать это в файле robots.txt. В панелях хостеров есть корневой каталог, в котором предусмотрена возможность редактирования файлов. При введении кода User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: / файл будет скрыт от копирования. При введении такого кода из веб-архива удаляется и текущая версия сайта и не осуществляется системное копирование (до тех пор, пока в файле robots.txt есть такие настройки или пока не закончится срок регистрации домена) |
| Восстановление веб-сайта из интернет-архива | Если сайт был поврежден вирусами или есть другие технические проблемы, из-за которых контент был нарушен, можно восстановить файлы из онлайн-хранилища. Для этого применяются специальные сервисы. Есть платные и бесплатные варианты, которые выбираются с учетом количества страниц для восстановления |

Уникальный контент из веб-архива
Многие коммерческие сайты через некоторое время существования закрываются. Если на них был опубликован полезный контент (экспертные статьи, аналитические обзоры и другая важная информация), то после закрытия первоисточника они могут быть востребованными. То есть, сайт уже не работает и ранее написанные статьи могут использоваться на информационных порталах (если они уникальны).
Веб-архив является очень полезным сервисом, который может пригодиться в различных ситуациях. Быстрое восстановление потерянных данных может значительно сэкономить время и финансы, если сайт подвергнется хакерской атаке или же перестанет работать из-за серьезной технической проблемы. Веб-архив дает возможность не только просматривать старые версии своего сайта, но и анализировать контент конкурентов, сохраненный в разные периоды времени.
Web Archive: как посмотреть, как выглядел сайт раньше?


Интернет в привычном для нас виде появился 36 лет назад — за это время он развивался семимильными шагами, а сайты тысячи раз меняли свой дизайн и контент. Web archive представляет собой своеобразную машину времени, которой может воспользоваться каждый пользователь.
Что такое Web Archive?
Это бесплатный сервис, где собраны истории многих интернет ресурсов — их архивные копии. Причем речь идет не о скриншотах, а о полноценных страницах с изображениями, рабочими ссылками и стилевым оформлением.
Получение информации о том или ином домене предполагает не только интересное времяпровождение с отслеживанием эволюции веб-проекта, но еще и возможность:
- узнать тематику сайта — архив интернета демонстрирует содержимое, благодаря чему легко определить нишу проекта;
- посмотреть, как выглядел сайт раньше — это находка для охотников за б/у доменами;
- определить, регистрировался ли до этого анализируемый домен — полезный инструмент для тех, кому принципиальна «стерильность» домена или для того чтобы избежать санкций поисковиков;
- восстановить свой сайт, если вы почему-то не сделали резервное копирование.
- отыскать уникальный контент — трудоемкая задача, которая может подарить вам десятки бесплатных статей;
- увидеть удаленный текст из закладок — шансы найти нужную страницу достаточно высоки.
История создания архива интернета
Wayback Machine является одним из двух главных проектов archive.org. Этот некоммерческий сервис был создан в 1996 году Брюстером Кейлом. Машина времени сайтов имеет четкую цель: сбор и хранение копий ресурсов вместе со всем контентом для возможности свободного просмотра несуществующих или неподдерживающихся страниц в будущем. С 1999-го робот стал фиксировать еще и аудио, видео, иллюстрации, программное обеспечение.
База современного архива собиралась в течение 20 лет, у нее не существует аналогов. Статистика впечатляет: на сегодняшний день в сервисе находится 279 миллиардов страниц, 11 миллионов книг и статей, 100 тысяч программ и миллион картинок.
А знаете ли вы? Веб-архив сайтов часто имеет проблемы на законодательном уровне из-за нарушения авторских прав. По требованию правообладателей библиотека удаляет материалы из публичного доступа.
Как пользоваться веб-архивом?
Сервис очень удобный в применении. Пошаговая инструкция такова:
- Зайдите на главную страницу платформы.
- Введите в поле название интересующего вас сайта и нажмите Enter (в нашем случае это https://livepage.pro).
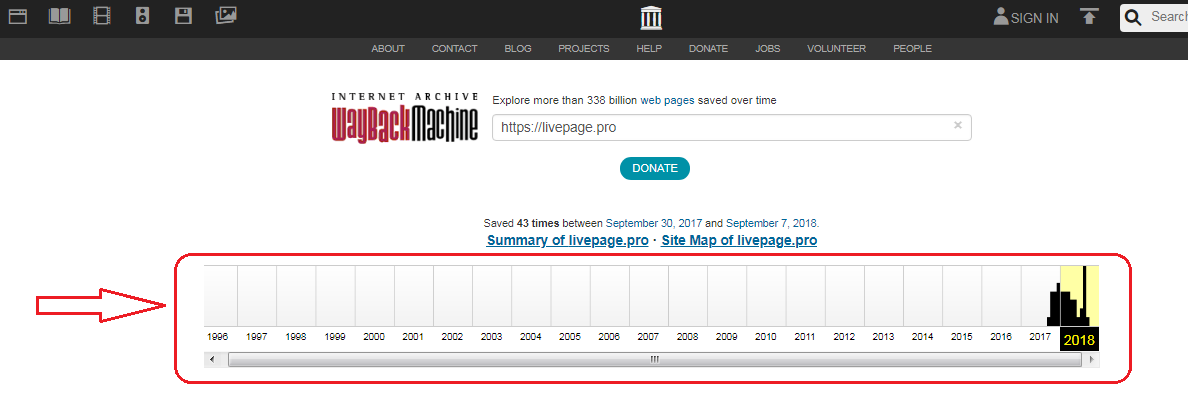
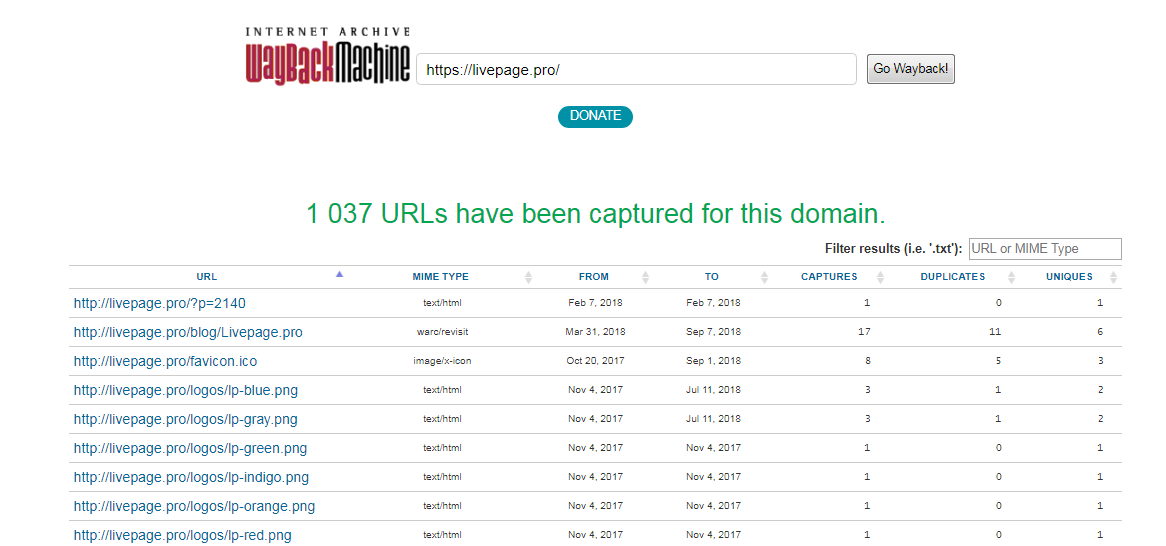
Под указанным доменным именем демонстрируется основная информация: когда начинается история проекта, сколько слепков имеет сайт. В примере видно, что ресурс был впервые архивирован 30 сентября 2017 года, библиотека хранит его 43 архивные копии.

Дальше мы обращаем внимание на календарь — голубым цветом в нем отмечены даты создания слепков.
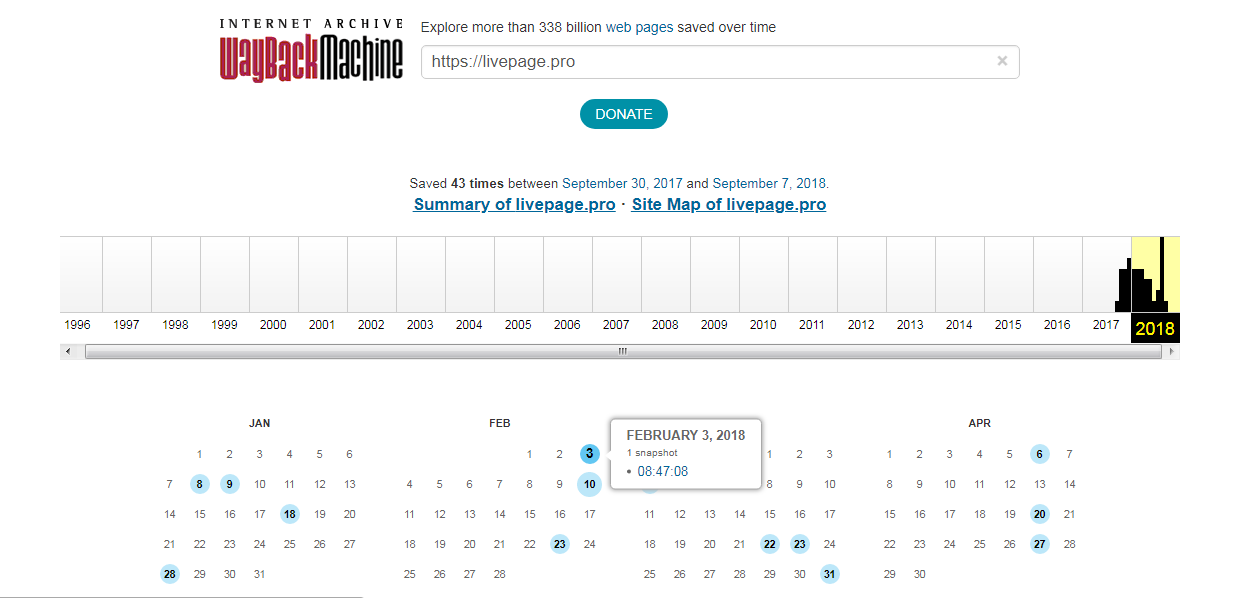
Каждый из них доступен для просмотра: нужно лишь выбрать год, месяц и день сохранения. Мы хотим посмотреть, как выглядел сайт раньше: допустим, 3 февраля текущего года. Наводим курсор на голубой кружок и жмем на время сохранения. Проще не бывает!
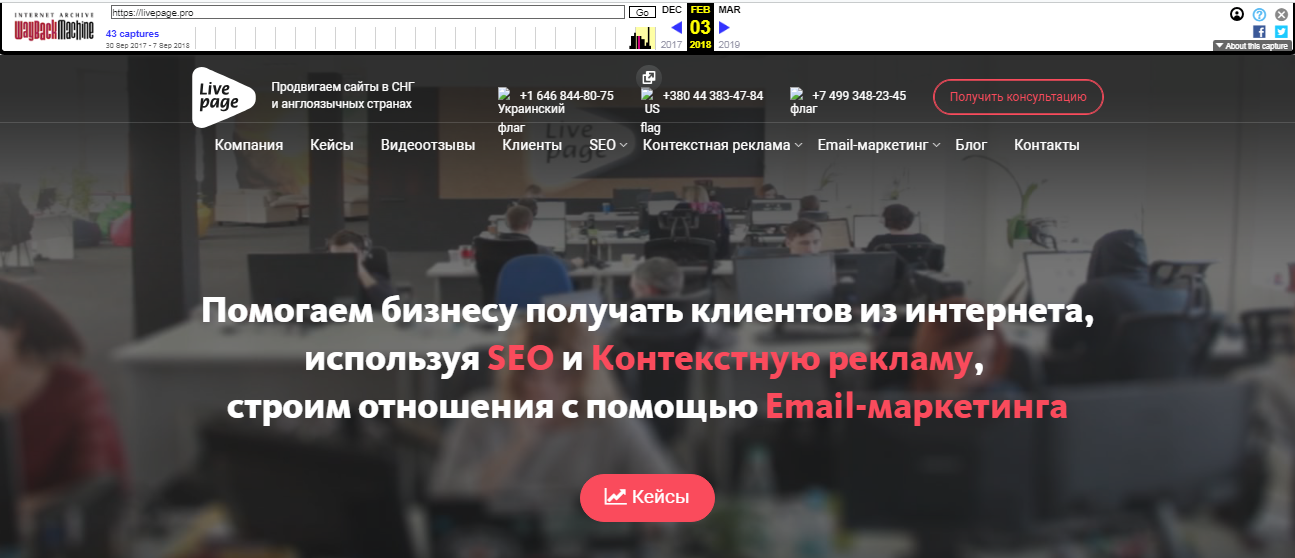
При желании можно получить общие данные о web-проекте — надо нажать на кнопку Summary над хронологической таблицей и календарем или же ознакомиться с картой сайта (кнопка Site Map).
Алгоритм действий можно сократить. Для работы с сервисом напрямую, введите в строке своего браузера
В нашем случае это
Как восстановить сайт из веб-архива?
Плохая новость для тех, кто планирует просто найти архив сайта и скачать его привычным способом: страницы имеют вид статических html-файлов, к тому же их слишком много для того, чтобы заниматься этим вручную. Решить проблему можно при помощи специальных программ, к примеру, приложения на ruby. Необходимо лишь установить все на сервер и запустить восстановление страниц.
- Установите «Руби».
apt-get install ruby

- Добавьте саму программу, необходимую для работы.
gem install wayback_machine_downloader
- Запустите выкачивание сайта из web archive.

wayback_machine_downloader http://www.site.ru -timestamp 20131209110704
Для удобства можно указать отметку снапшота — утилита определит число страниц и выведет выкачиваемые файлы на консоль. После скачивания и сохранения мы получим набор статических данных.
- Разместите файлы в выбранной папке. Подойдет rsync:
rsync -avh./websites/www.site.com/ /var/www/site.com/
- Создайте конфигурацию в nginx и дождитесь обновления dns. На этом все!

Как восстановить сайт без бэкапа?
Вернуть ресурс из небытия можно даже без резервного копирования.
-
Как уже говорилось раньше, можно восстановить сайт из веб-архива https://archive.org. Чтобы получить все страницы, введите в специальное поле имя ресурса с добавлением /* (https://livepage.pro/*). Здесь же предусмотрена возможность фильтрации файлов по подстроке в URL. Для скачивания файлов подойдут многие программы, например, Teleport Pro.
Войдите в режим расширенного поиска и укажите имя сайта. Получив результаты, кликайте по ссылкам «cached» или «копия».
- Если вы отдаете полный RSS, тогда стоит проверить еще и ридеры, агрегаторы.
Учтите!
Нужный вам проект может и не входить в архив сайтов интернета. Если вы его не нашли в библиотеке — значит, правообладатель потребовал удаления копий или же ресурс закрыли в соответствии с законом о защите интеллектуальной собственности. Возможен и другой вариант: через файл robots.txt был банально внесен соответствующий запрет.
Как найти уникальный контент из веб-архива для вашего сайта?
Статьи, расположенные на заброшенных ресурсах, обычно не представляют никакой ценности для их бывших владельцев. А ведь в мир иной ежедневно уходят десятки сайтов. И среди кучи хлама, выброшенного на помойку истории, можно найти настоящие самородки — приличные тексты, которые достанутся вам бесплатно.
Поисковики хорошо относятся к любому актуальному и уникальному контенту — можно не бояться попасть в их немилость только из-за того, что статьи взяты из веб-архива чужого сайта.
Итак, последовательность действий следующая:
- Найдите подходящие вам блоги. Для этого следует зайти на Reg.ru и скачать оттуда список недавно освободившихся доменов.
- Посетите архив интернета с целью поиска сохраненных копий.
- Проверьте понравившиеся тексты через антиплагиат (контент может быть уже скопирован на другие сайты).
- Опубликуйте уникальные статьи на своем ресурсе.
При разумном подходе такой способ пополнения сайта контентом можно поставить на поток. Поиски материалов на мертвых блогах оправданы экономией времени на написание текстов и денег, которые бы вам пришлось заплатить авторам.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива?
Если вы дорожите контентом и не хотите видеть свою онлайн-площадку в электронной библиотеке, пропишите запретную директиву в файле robots.txt:
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /
После изменения в настройках веб-сканер перестанет создавать архивные копии вашего сайта, к тому же удалит уже сделанные слепки. Однако учтите, что ваш запрет действует лишь до тех пор, пока доступен robots.txt — когда закончится срок регистрации доменного имени, машина времени сайтов станет демонстрировать статьи всем желающим.
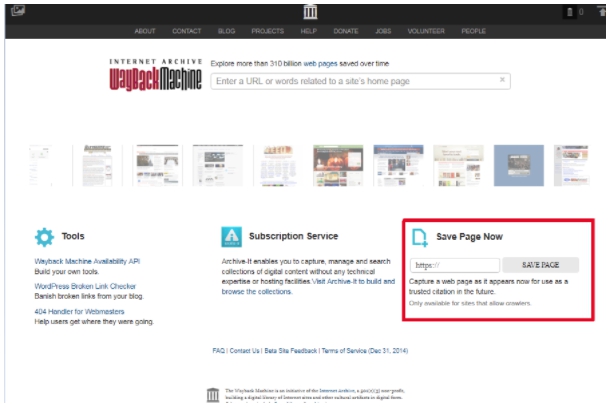
Важно! Если вы, наоборот, желаете активно пользоваться веб-архивом, введите соответствующий запрос на главной странице сервиса. Просто укажите адрес проекта в разделе Save Page Now, после чего нажмите кнопку Save Page. Повторяйте процедуру после внесения любых правок.
Аналоги Webarchive
Альтернативой рассматриваемой в обзоре электронной библиотеке может стать:
9 способов найти удаленный сайт или страницу

Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
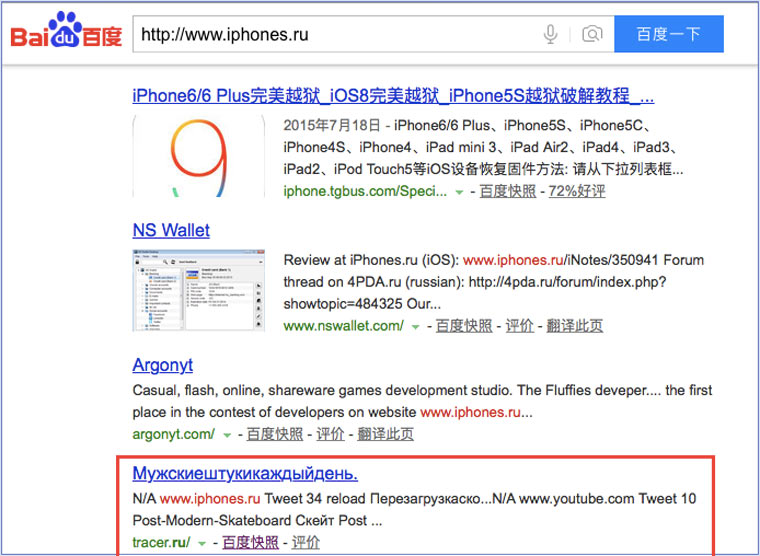
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
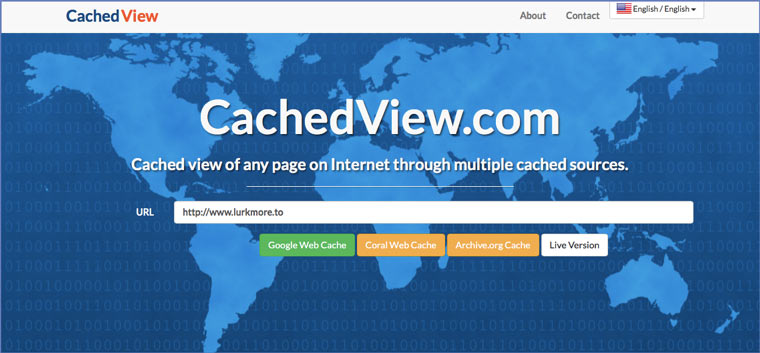
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
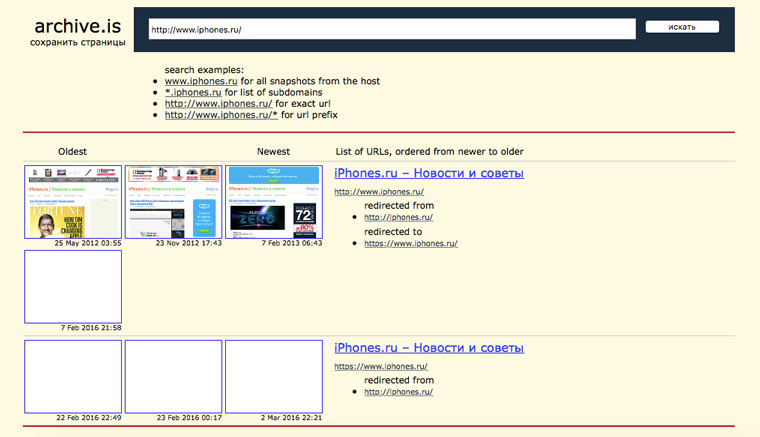
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
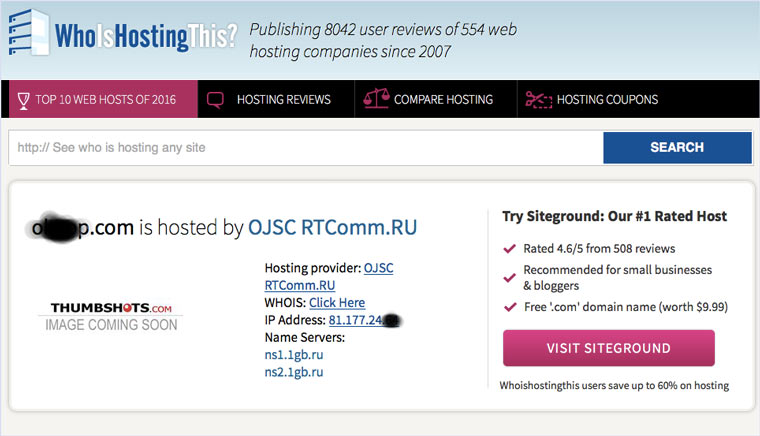
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com: 
ВЕБ-архив

2021-06-29 • 9 мин читать
WebArchive — огромная бесплатная библиотека, в которой хранятся web-архивы сайтов — миллиарды страниц, в том числе те, которых уже нет в Яндекс и Google. Это живая история интернета, поскольку в Web-архиве можно посмотреть старую версию сайта, узнать, какой контент размещался на интересующем домене и даже восстановить удаленные документы.
Что такое веб-архив?
Организатор и идейный вдохновитель веб-архива сайтов — американец Брюстер Кейл. Internet Archive («Архив интернета») — некоммерческий проект, его цель — сохранить мировое культурное и интеллектуальное наследие. По данным Википедии, этот сервис был создан в 1996 году. Во всемирном архиве интернета хранятся литературные произведения, видеозаписи, изображения, которые свободно публикуются в Сети. Это один из разделов огромного сервиса archive.org.
Боты постоянно сканируют всемирный интернет и пополняют библиотеку. Роботам помогают живые сотрудники и партнеры. Добавить копии страничек в веб-архив интернета может любой желающий. Конечно, в библиотеке невозможно найти абсолютно все страницы, которые когда-то были созданы. Но их там очень много — более 580 миллиардов.
Просмотреть архив «машины времени» («Wayback Machine» — второе название web-архива сайтов) можно бесплатно. При этом пользователям предлагают перейти по ссылке «Пожертвовать» и перевести создателям уникального сервиса посильную сумму.
Возможности сервиса
Для вебмастера и SEO-специалиста бесплатные всемирные архивы открывают ряд полезных возможностей.
- Если планируется купить домен или интернет-проект, важно посмотреть историю сайта. В ней могут быть «криминальные» эпизоды. Например, распространение пиратских видеозаписей, продажа запрещенных товаров или адалт-контент. «Темное прошлое» может негативно сказаться на продвижении проекта в поисковых системах.
- Архив веб-страниц поможет при выборе дроп-домена. В сервисе можно посмотреть бесплатно, какой проект на нем располагался (коммерческий, информационный) и как он выглядел.
- Можно узнать историю конкурентов. Сравнивая архивы сайтов с их современной версией, легко понять, как менялась ниша, как трансформировались проекты.
- Есть возможность проследить и проанализировать изменения на собственном сайте и даже восстановить измененный по ошибке URL.
- С помощью дополнительных сервисов можно восстановить удаленный ресурс или отдельные страницы.
- А также найти контент по интересующей теме, которого уже нет в глобальной сети.
Как посмотреть архивные страницы?
Откройте в браузере https://web.archive.org/. В строке для поиска укажите URL главной или любой другой страницы нужного сайта.
Сервис покажет график сохранений и календарь, в котором обведены даты сканирований. Эти даты не связаны с датами обновления контента. Боты работают по собственному графику.
Если кликнуть на нужный год и дату, сервис покажет web-версию старых страниц. Обычно сохраняется не весь контент, часть документов недоступна, отображаются не все фотографии и картинки. Часть ссылок кликабельны, можно погулять по интернет-площадке, перейти в другие разделы.
Если вы не знаете точный адрес нужного ресурса или хотите изучить целую нишу, нужно набрать в поисковой строке главные ключевые слова. Архив бесплатно найдет сайты нужной тематики. Перейдите по ссылкам этого списка и изучайте историю интересующего проекта.
Существует приложение Wayback Machine («Машина времени») для iOS и Android. Приложение скачивают на мобильное устройство. В нем заложен тот же функционал, что и в десктопной версии.
Как добавить страницу в сервис?
Боты обходят интернет по собственному графику. Не все проекты попадают в историю «Машины времени». Молодые площадки с небольшим трафиком редко оказываются в библиотеке. А если и попадают туда, то частота сканирований очень низкая — раз в несколько месяцев.
Сохранять копии сайта в WebArchive можно самостоятельно. Для этого нужно открыть сервис, найти поле «Сохранить страницу» и добавить туда URL. Снимки появятся в библиотеке через пару минут.
Эту операцию можно периодически повторять.
В будущем эти копии будут полезны, чтобы отслеживать изменения в дизайне, структуре, контенте. Если страницы будут по ошибке удалены, а бэкапы не делались или были утеряны, архивные снимки помогут восстановить документ.
Как удалить копии страниц своего проекта?
Не всем и не всегда хочется выкладывать историю своей веб-площадки на всеобщее обозрение. Например, на сайте могла быть выложена ошибочная, некорректная или противозаконная информация. Даже если удалить страницу или файл, они сохранятся в библиотеке.
Архивом страниц могут заинтересоваться конкуренты и недоброжелатели. Поэтому многим хочется удалить копии веб-документов из сервиса.
Раньше вебмастера вписывали в robots.txt запрещающую директиву для ботов. Но сейчас это уже не работает.
Убрать страницы из библиотеки можно только через саппорт. Для этого нужно написать письмо на info@archive.org. Писать нужно по-английски, с указанием реальных имени, фамилии, физического адреса. Чтобы подтвердить, что вы владелец ресурса, отправлять письмо лучшего с почтового ящика, указанного на сайте. Еще один способ подтвердить свои права — написать через регистратора домена или через хостинг. Иногда саппорт просит прислать копию паспорта.
Через поддержку можно навсегда запретить делать копии своего проекта.
Как восстановить сайт из архива?
Если вы сами загрузили копию страницы, ее можно найти в своем аккаунте в разделе «Мой архив».
Чтобы скачать страницу, найдите ее в списке, кликните по виджету справа и сохраните документ в виде html-файла.
С чужими сайтами действуют примерно так же: открывают копию в архиве, через панель разработчика копируют html-код, стили, изображения.
Файлы заливаются по FTP в корневую директорию домена на хостинге.
Но ручной способ слишком долгий и трудоемкий. Автоматизировать процесс можно через платные онлайн сервисы: Archivarix, waybackmachinedownloader, r-tools, rush-analytics и другие. Здесь можно не только скачать файлы, но и оптимизировать их: убрать битые ссылки, неработающие скрипты и так далее. Некоторые сервисы умеют импортировать файлы в WordPress.
Другие полезные опции
WebArchive умеет не только сохранять копии и показывать старую версию страниц сайта. Здесь есть несколько полезных инструментов аналитики.
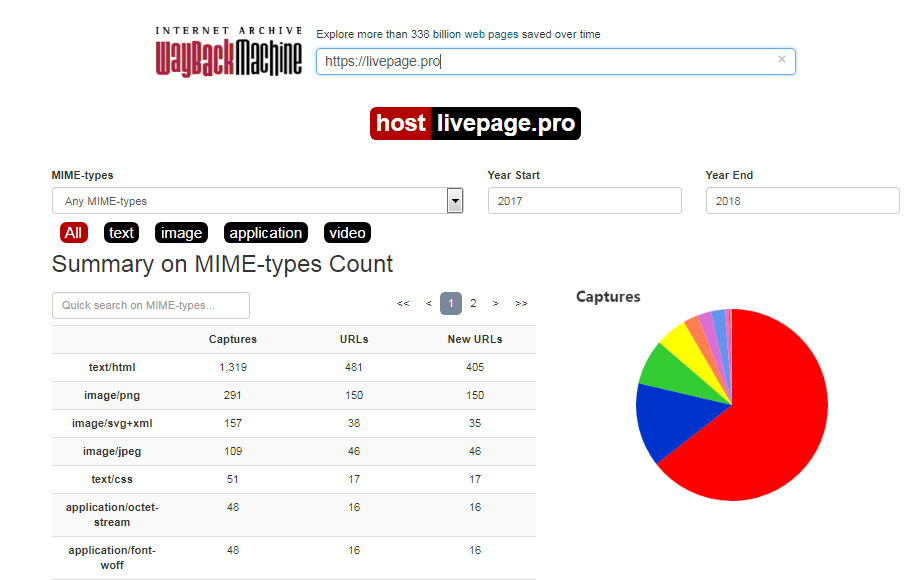
- Сводка. Сервис показывает, какие данные содержит сайт: сколько на нем текстов, изображений, приложений. Можно открыть и просмотреть список всех URL.
- Изменения. Инструмент поможет выявить изменения в URL-адресах. Для этого надо выбрать архивы на разные даты и сравнить старшие копии с младшими. Изменения будут выделены цветом.
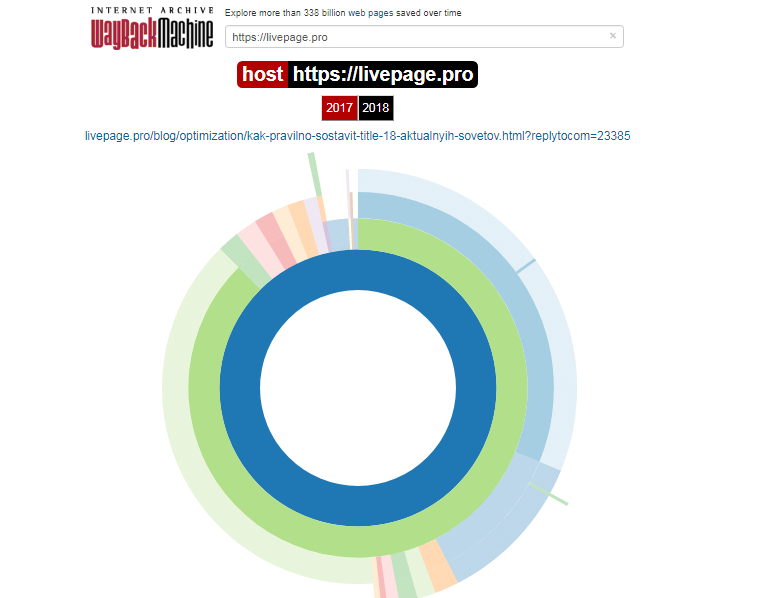
- Карта сайта. Группирует данные по годам и строит карту в виде круговой диаграммы для каждого года.
В центре диаграммы корень сайта, а кольца — это разделы и страницы. Диаграмма кликабельна, она позволяет перейти на копию нужного URL.
Читайте на Askusers
Как быстро и правильно провести A/B-тестирование в маркетинге и SEO? Что можно тестировать, какие инструменты использовать и как замерять результат?
Что такое коммерческие факторы ранжирования, как они влияют на трафик и конверсию и как их улучшить?
Если страницы выпали из индекса поисковых систем — это тревожный признак, надо срочно искать причину. Подробный алгоритм проверки.